
Prepared Statements, Connection Pooling and Npgsql 3.2
Prepare Thy Statements
Preparing your statements in PostgreSQL is important.
Really important.
Let’s jump right in with some pgbench benchmarking of unprepared vs. prepared:
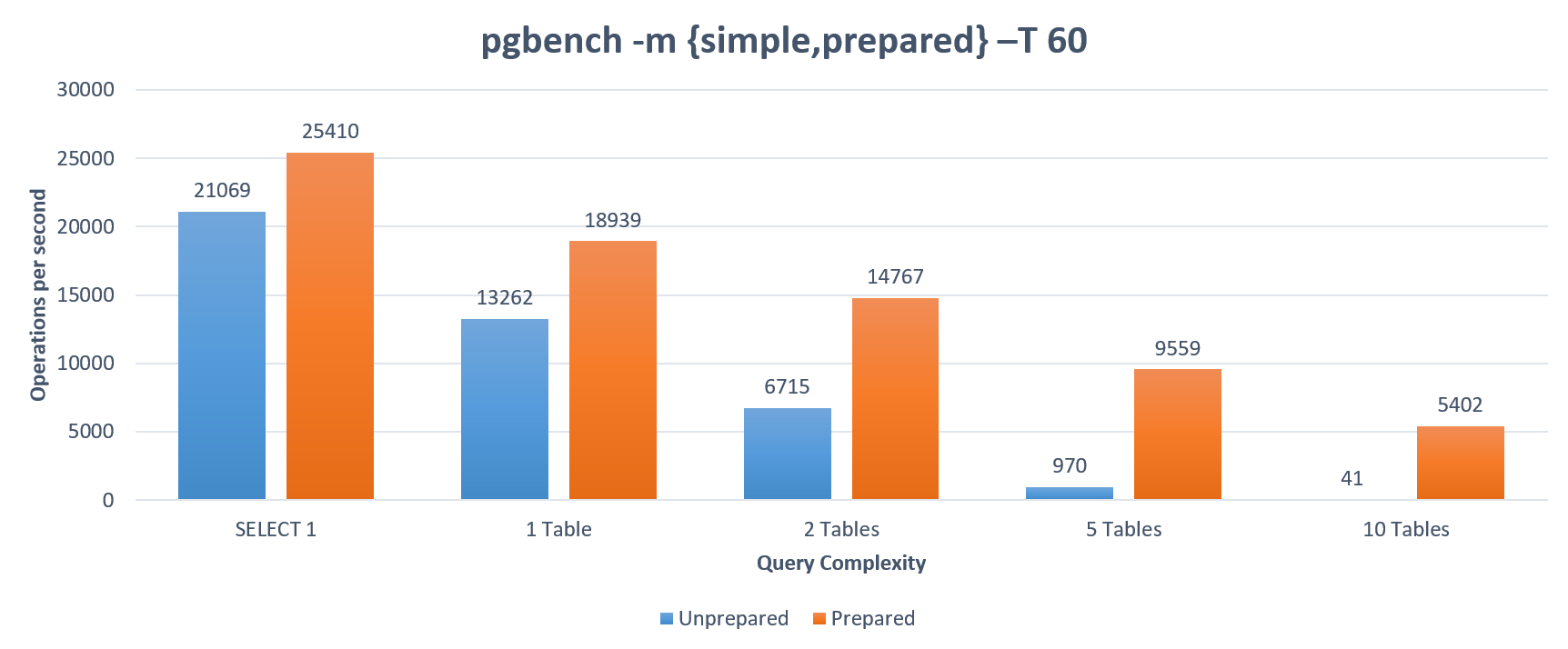
This queries execute have increasing degrees of complexity, from a trivial SELECT 1 to a join of 10 tables. As you can see, when joining 5 tables, preparation improves performance tenfold. The SQL executed in this scenario is:
SELECT table0.data+table1.data+table2.data+table3.data+table4.data
FROM table0
JOIN table1 ON table1.id=table0.id
JOIN table2 ON table2.id=table1.id
JOIN table3 ON table3.id=table2.id
JOIN table4 ON table4.id=table3.id
Some caveats (or, why I am being manipulative):
- Executing benchmarks against localhost eliminates network latency, which is a significant part of most real-world applications. Running the same benchmark over the network should show a much less dramatic performance improvement, as latency starts to occupy a more significant part of the execution time.
- Also, if PostgreSQL actually had to crunch through any data (or even worse, access any disks), the weight of query planning would be further decreased.
But even with these caveats, the picture is pretty clear. Somewhat surprisingly, even in the trivial scenario, SELECT 1, there’s a 17% performance increase - nothing to sneeze at - and this constitutes the baseline: any other query you can imagine will only benfit more from preparation.
Note that this dramatic situation isn’t universal across databases. In SQL Server, for example, “the prepare/execute model has no significant performance advantage over direct execution”, since SQL Server internally reuses execution plans regardless of whether you explicitly prepare or not. As a result, SQL Server devs moving to PostgreSQL can experience a severe “performance degradation” since their code doesn’t prepare (database portability really isn’t a trivial thing).
Prepared Statements and Connection Pooling
Hopefully the above convinced you to prepare all statements that you execute repeatedly. But if you’re using connection pooling (and who isn’t), there’s a complication. In Npgsql 3.1 and below, when you close a pooled connection, Npgsql resets the connection to avoid leakage of state. For example, you may have changed some PostgreSQL parameter (e.g. statement_timeout) from its default; if your change isn’t reset when the connection is returned to the pool, the next guy to receive that physical connection may get some nasty, unpredictable surprises. In other words, to get sane, deterministic behavior, we want a newly-opened pooled connection to be as similar as possible to a newly-opened physical connection. In PostgreSQL, resetting connection state can be done via the DISCARD ALL command, which is perfect except for one tiny detail - it also closes all prepared statements.
That’s right, all the performance boost discussed above goes right down the toilet. But DISCARD ALL isn’t the whole problem. Even if we were to skip it, someone still needs to track which prepared statements exist for a given (physical) connection, and reuse a previously-existing prepared statement when its SQL is executed again. Say I prepared some SQL, and then returned my connection to the pool. The next time the connection is opened, someone needs to know that that same SQL has already been prepared, and what that prepared statement’s name is. There needs to be tracking involved here.
Npgsql 3.2 implements persistent prepared statements. Prepared statements no longer die when you dispose the NpgsqlCommand which created them - they continue living, and are internally tracked by Npgsql. When you execute Prepare() a second time, Npgsql will locate the prepared statements in the internal, per-connection data structures, and no actual preparation will need to take place. This allows you to benefit from statements prepared in previous lifetimes, providing all the performance benefits to applications using connection pools.
“But wait”, you say, “what about DISCARD ALL? All that fuss about resetting the connection and preventing state leak?”. Good question. When resetting the connection, if there’s at least one prepared statement, Npgsql won’t send DISCARD ALL, it will send a series of other commands which are the equivalent of DISCARD ALL, minus closing the prepared statement (you can see the actual reset statements in the PostgreSQL docs). Note that all this isn’t an additional roundtrip imposed on you; when you close a pooled connection, DISCARD ALL (or the almost-equivalent series above) is simply written to Npgsql’s internal write buffer, and will be sent prepended to the first actual statement sent when the connection is reopened. This allows us to reset state with a minimal performance impact. If, however, you truly want to squeeze every bit of performance and don’t care about resetting the state, pass the No Reset On Close parameter in your connection string, and Npgsql won’t even prepend.
One last note. The above works well because Npgsql manages its own connection pool, and can remember things for each physical connection (i.e. which statements have been prepared). Unfortunately, if you’re using an external connection pool such pgbouncer, you’re outta luck. As far as Npgsql is concerned, each connection it makes is a new physical connection - even if pgbouncer provides pooling behind the scenes. When opening a new connection to pgbouncer, Npgsql has no way of knowing which statements have already been prepared and what their names are - so prepared statements are pretty much unusable in this scenario. In theory it’s possible to query PostgreSQL to know which prepared statements exist, but that would be another roundtrip affecting performance.
Prepared Statements and O/RMs
So prepared statements play well with Npgsql’s connection pool, great. But preparation depends on, well, somebody actually preparing. Unfortunately, unless you’re coding directly against Npgsql (or the ADO.NET API), there’s a good chance preparation is out of the question. Dapper, for example, does not expose any sort of API for preparation, and the same is true of Entity Framework Core. In a way, the point of these layers is to hide the details of commands from the developer, but in doing so they also hide access to this important performance-boosting mechanism.
Inspired from the PostgreSQL JDBC driver, Npgsql 3.2 provides automatic preparation as well. This opt-in feature will make Npgsql track the SQL statements you execute, and once a statement is executed enough times (5 by default), bingo - Npgsql transparently prepares it. From that point on, all executions of that statement will be prepared. However, we obviously don’t want to prepare too many statements, since those have a resource cost at the PostgreSQL side. So you define the maximum number of automatically-prepared statements you’re willing to have, and beyond that number Npgsql will simply eject the least-recently used one to make room for the newcomer. This provides the performance benefits of preparation without requiring anyone to actually call Prepare().
However, note that explicitly preparing your statement is still a little better than letting Npgsql do so, which is one reason why automatic preparation is off by default. Turn it on by setting the Max Auto Prepare parameter to non-zero in your connection string.
Summary
Definitely embrace prepared statements - not doing so amounts to criminal negligence. Of course, prepare responsibly, measuring performance and making sure you’re not overloading the server with too many prepared statements; but do prepare. If you’re using Dapper, Entity Framework Core or any other data layer that doesn’t prepare, turn on automatic preparation to get a significant performance boost without touching a single line of code.
And to to finish this long and preachy blog post, here’s an Npgsql benchmark which compares unprepared, automatically prepared and explicitly prepared performance in various query complexity scenarios, running against localhost (the benchmark is included in Npgsql’s benchmarking suite):
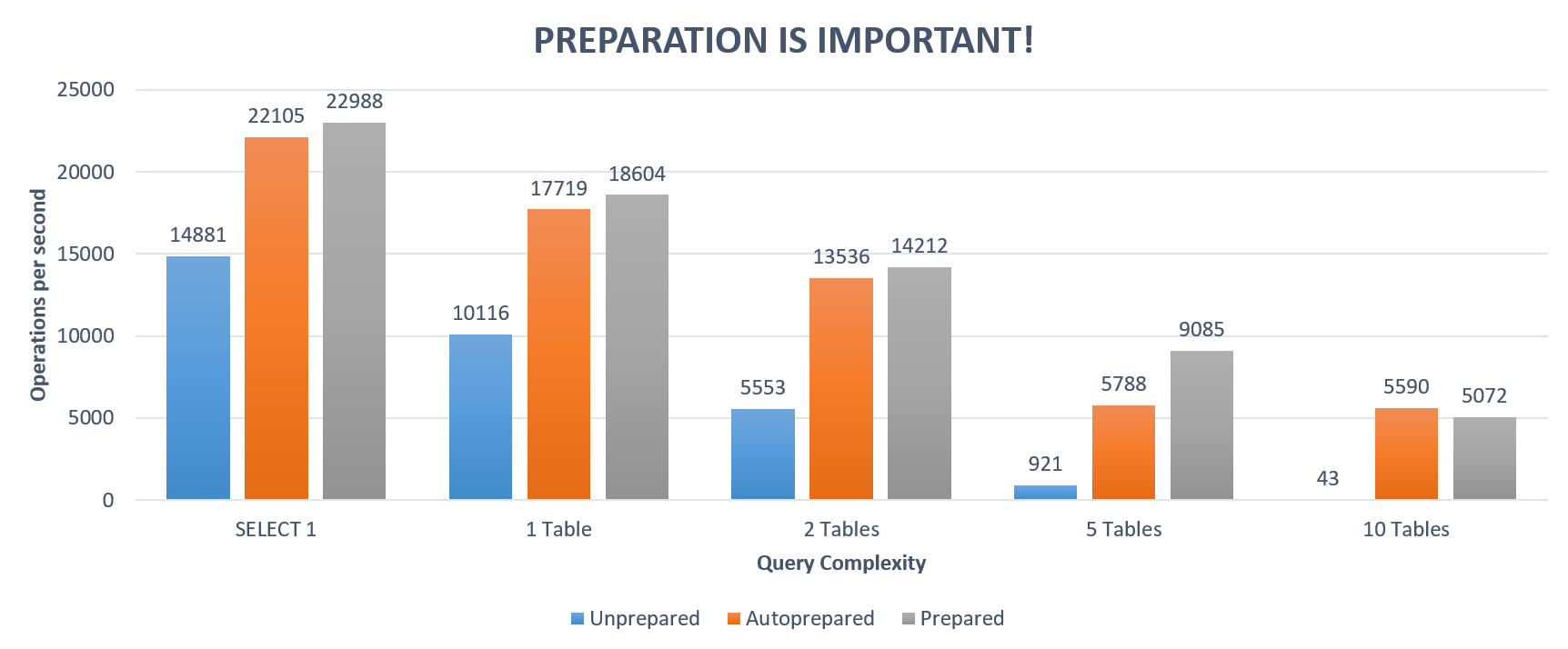
And the detailed results:
BenchmarkDotNet=v0.10.1, OS=Microsoft Windows NT 6.2.9200.0
Processor=Intel(R) Core(TM) i7-3630QM CPU 2.40GHz, ProcessorCount=8
Frequency=2338449 Hz, Resolution=427.6339 ns, Timer=TSC
[Host] : Clr 4.0.30319.42000, 64bit RyuJIT-v4.6.1586.0
DefaultJob : Clr 4.0.30319.42000, 64bit RyuJIT-v4.6.1586.0
| Method | TablesToJoin | Mean | StdErr | StdDev | Op/s | Scaled | Scaled-StdDev | Allocated |
|---|---|---|---|---|---|---|---|---|
| Unprepared | 0 | 67.1964 us | 0.1586 us | 0.6142 us | 14881.75 | 1.00 | 0.00 | 1.9 kB |
| AutoPrepared | 0 | 45.2367 us | 0.0328 us | 0.1182 us | 22105.94 | 0.67 | 0.01 | 816 B |
| Prepared | 0 | 43.5007 us | 0.2466 us | 0.9227 us | 22988.13 | 0.65 | 0.01 | 305 B |
| Unprepared | 1 | 98.8502 us | 0.1278 us | 0.4949 us | 10116.32 | 1.00 | 0.00 | 1.93 kB |
| AutoPrepared | 1 | 56.4359 us | 0.0617 us | 0.2388 us | 17719.23 | 0.57 | 0.00 | 866 B |
| Prepared | 1 | 53.7518 us | 0.0486 us | 0.1818 us | 18604.04 | 0.54 | 0.00 | 306 B |
| Unprepared | 2 | 180.0599 us | 0.2990 us | 1.1579 us | 5553.71 | 1.00 | 0.00 | 2.06 kB |
| AutoPrepared | 2 | 73.8756 us | 0.2004 us | 0.7760 us | 13536.27 | 0.41 | 0.00 | 968 B |
| Prepared | 2 | 70.3609 us | 0.1715 us | 0.6417 us | 14212.44 | 0.39 | 0.00 | 306 B |
| Unprepared | 5 | 1,084.6065 us | 1.1822 us | 4.2626 us | 921.99 | 1.00 | 0.00 | 2.37 kB |
| AutoPrepared | 5 | 172.7463 us | 5.6496 us | 56.2132 us | 5788.84 | 0.16 | 0.05 | 1.27 kB |
| Prepared | 5 | 110.0652 us | 0.1098 us | 0.3805 us | 9085.52 | 0.10 | 0.00 | 308 B |
| Unprepared | 10 | 23,086.5956 us | 37.2072 us | 139.2167 us | 43.32 | 1.00 | 0.00 | 3.11 kB |
| AutoPrepared | 10 | 178.8742 us | 0.1960 us | 0.7592 us | 5590.52 | 0.01 | 0.00 | 1.77 kB |
| Prepared | 10 | 197.1392 us | 0.3044 us | 1.1790 us | 5072.56 | 0.01 | 0.00 | 308 B |
Thanks to Vladimir Sitnikov of the PostgreSQL JDBC driver project, for suggesting some of the ideas above.
Comments